Enterprise Artificial Intelligence
Overview
Machine Learning (ML) is a category of Artificial Intelligence (AI), computer science, and mathematics that focuses on using data and algorithms to train models and use those models to make predictions on new and unseen data. Infor AI opens up the world of machine learning to a wider array of business users through its visual modeler, allowing for deployment of models with low-code and no-code implementations.
Key Concepts & Definitions
| Infor AI | Infor’s machine learning platform, a component of Infor OS. |
| Quest | A flow of activities that make up the machine learning model. |
| Training Quest | A quest involving a predictive method that produces a trained model. |
| Trained Model | A model that can be used to predict outcomes based on new data. |
| Production Quest | A trained model that has taken steps to deployment. |
| Endpoint | The REST API access point of a real time production quest to process new data through the model. Endpoints can process data by being passed a CSV, a JSON message, or accessed via the API gateway. |
| Data Lake | Flexible and economical cloud object storage solution where data is stored in its raw format. This is Infor AI’s primary data source. |
| Label/Target | Terms that refer to the prediction of the model. |
| Categorical | Data types that are non-numeric in nature and belong to a category instead. E.g. “Country of Residence”. |
| Supervised Learning | Machine learning algorithms that form relationships between targeted label and input features so that the output values for unseen data can be predicted. Supervised algorithms must be trained on known outcomes. |
| Unsupervised Learning | Machine learning algorithms that make inferences from data using only input features without referring to known or labelled outcomes. These algorithms can discover data structures by clustering it into intuitive groups. |
Best Practices
A machine learning project has a lot of flexibility and user control over it, but it is generally accepted that an ML workflow adopt the product life cycle below.

Business Case Definition
Before starting a machine learning project, it is best to step back and define the business problem at hand. It takes some finesse to match business problems with the appropriate algorithms, and the appropriate data. Often, business problems fall into one of the following categories.

Fetching Data
The enterprise can produce incredible amounts of data from different systems. For use in the Infor AI platform, data should be managed and stored in the data lake.
Data Preparation
Data preparation tasks can be numerous and time consuming. It is recommended that one be familiar with tidy data standards when it comes to cleaning data. It is also important to understand any caveats to the particular algorithm that you might use to process the data. Infor AI has the following built in tools for data manipulation and preparation, as well as the ability to run python scripts to allow for complete customization when manipulating data.
| Data Block | Description |
|---|---|
| Select Columns | Select or exclude a subset of columns from the current dataset. |
| Remove Duplicates | Remove duplicates in selected features. |
| Construct Feature | Create a new feature out of the existing ones by using mathematical, logical, or casting operations. |
| Index Data | Transform categorical values into numeric for the selected columns. Each category will be assigned a number according to its occurrence in the data, highest occurrence having number 0. |
| Smooth Data | Remove noise from a dataset to allow natural patterns to stand out. |
| Split Data | Split the dataset into training data and test data by specifying the split ratio for the training dataset. |
| Scripting | Execute a customized Python script to perform an activity which is not available in the catalog. |
| Ingest to Data Lake | Ingest data to Infor Data Lake |
| One Hot Encoder | Transform categorical features into a binary matrix (vectors) to distinguish each categorical label. The vector consists of 0s in all cells, with the exception of a single 1 in a cell used uniquely to identify the label. |
| Feature Scaling | Scale features with varying magnitudes, units and range into normalized values. |
| Handle Missing Data | Replace missing values in selected features (with mean / mode / constant value / interpolation), or remove the entire row exceeding a selected ratio of missing data. |
| Target Encoder | Numerization of categorical variables via target – replaces the categorical variable with just one new numerical variable and replaces each category of the categorical variable with its corresponding probability of the target (if categorical) or average of the target (if numerical) |
| Edit Metadata | Select the Target label. Edit the metadata of the selected features by changing its data type, tagging the categorical values, changing the variable name or defining their machine learning type. |
| Balance Data | Balance the dataset using undersampling or oversampling methods. |
| Execute SQL | SQL operations (filter out data, join datasets, aggregate data etc.). |
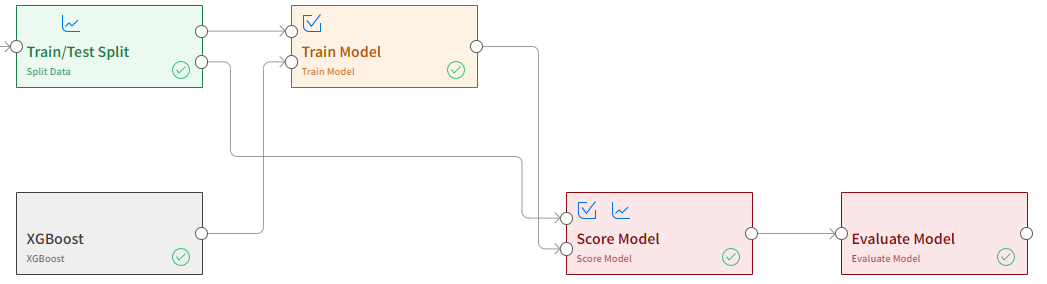
Model Training
Training a model requires the prepared dataset and the algorithm to be used in training. Supervised algorithms can be scored for accuracy using the train/test split functionality and the score and evaluate model blocks. The compare model block will allow for the training of multiple models to compare performance statistics.
Model Fitting & Tuning
Algorithm hyperparameters are available in each of the algorithm blocks. The specific parameters will be different depending on algorithm selection, and can details for each hyperparameter can be found in the documentation of the chosen algorithm.
Model Deployment
In the quest, select the checkbox on activities desired for the deployed model and push the activities to the production quest. This quest can be deployed as an endpoint accessible via the ION API gateway.
Model Maintenance
Want to learn more?
Quick Reference
There is a lot to learn in the Infor Platform. A quick reference sheet is always helpful. Check out this Cheat Sheet.
Topical videos
Need information on a specific feature or function? Or how about a quick overview? Then short videos may be just what you are looking for. Check out our playlist on YouTube.
Product Documentation
Product documentation is the go-to reference for how specific parts of the product work. For online, searchable, easy to understand docs see this component’s Documentation.
Community
Collaborating with others in your industry is a great way to learn and help others. Start participating in this component’s online Community.